Usage
Requirements
A distributed Apache HBase installation depends on a running Apache ZooKeeper and HDFS cluster. See the documentation for the Stackable Operator for Apache HDFS how to set up these clusters.
Deployment of an Apache HBase cluster
An Apache HBase cluster can be created with the following cluster specification:
apiVersion: hbase.stackable.tech/v1alpha1
kind: HbaseCluster
metadata:
name: simple-hbase
spec:
version: 2.4.12-stackable0.1.0
hdfsConfigMapName: simple-hdfs-namenode-default
zookeeperConfigMapName: simple-hbase-znode
config:
hbaseOpts:
hbaseRootdir: /hbase
masters:
roleGroups:
default:
selector:
matchLabels:
kubernetes.io/os: linux
replicas: 1
regionServers:
roleGroups:
default:
selector:
matchLabels:
kubernetes.io/os: linux
replicas: 1
restServers:
roleGroups:
default:
selector:
matchLabels:
kubernetes.io/os: linux
replicas: 1
---
apiVersion: zookeeper.stackable.tech/v1alpha1
kind: ZookeeperZnode
metadata:
name: simple-hbase-znode
spec:
clusterRef:
name: simple-zk-
hdfsConfigMapNamereferences the config map created by the Stackable HDFS operator. -
zookeeperConfigMapNamereferences the config map created by the Stackable ZooKeeper operator. -
hbaseOptsis mapped to the environment variableHBASE_OPTSinhbase-env.sh. -
hbaseRootdiris mapped tohbase.rootdirinhbase-site.xml.
Please note that the version you need to specify is not only the version of HBase which you want to roll out, but has to be amended with a Stackable version as shown. This Stackable version is the version of the underlying container image which is used to execute the processes. For a list of available versions please check our image registry. It should generally be safe to simply use the latest image version that is available.
Monitoring
The managed HBase instances are automatically configured to export Prometheus metrics. See Monitoring for more details.
Configuration Overrides
The cluster definition also supports overriding configuration properties and environment variables, either per role or per role group, where the more specific override (role group) has precedence over the less specific one (role).
| Overriding certain properties which are set by operator can interfere with the operator and can lead to problems. |
Configuration Properties
For a role or role group, at the same level of config, you can specify: configOverrides for the following files:
-
hbase-site.xml -
hbase-env.sh
For example, if you want to set the hbase.rest.threads.min to 4 and the HBASE_HEAPSIZE to two GB adapt the restServers section of the cluster resource like so:
restServers:
roleGroups:
default:
config: {}
configOverrides:
hbase-site.xml:
hbase.rest.threads.min: "4"
hbase-env.sh:
HBASE_HEAPSIZE: "2G"
replicas: 1Just as for the config, it is possible to specify this at role level as well:
restServers:
configOverrides:
hbase-site.xml:
hbase.rest.threads.min: "4"
hbase-env.sh:
HBASE_HEAPSIZE: "2G"
roleGroups:
default:
config: {}
replicas: 1All override property values must be strings. The properties will be formatted and escaped correctly into the XML file, respectively inserted as is into the env.sh file.
For a full list of configuration options we refer to the HBase Configuration Documentation.
Phoenix
The Apache Phoenix project provides the ability to interact with HBase with JBDC using familiar SQL-syntax. The Phoenix dependencies are bundled with the Stackable HBase image and do not need to be installed separately (client components will need to ensure that they have the correct client-side libraries available). Information about client-side installation can be found here.
Phoenix comes bundled with a few simple scripts to verify a correct server-side installation. For example, assuming that phoenix dependencies have been installed to their default location of /stackable/phoenix/bin, we can issue the following using the supplied psql.py script:
/stackable/phoenix/bin/psql.py \
/stackable/phoenix/examples/WEB_STAT.sql \
/stackable/phoenix/examples/WEB_STAT.csv \
/stackable/phoenix/examples/WEB_STAT_QUERIES.sqlThis script creates a java command that creates, populates and queries a Phoenix table called WEB_STAT. Alternatively, one can use the sqlline.py script (which wraps the sqlline utility):
/stackable/phoenix/bin/sqlline.py [zookeeper] [sql file]The script opens an SQL prompt from where one can list, query, create and generally interact with Phoenix tables. If the script is run from a pod running a Stackable Hase image then the ZooKeeper quorum can be resolved automatically as Phoenix has access to the local HBase configuration details.
To query the table that was created in the previous step, start the script and enter some SQL at the prompt:
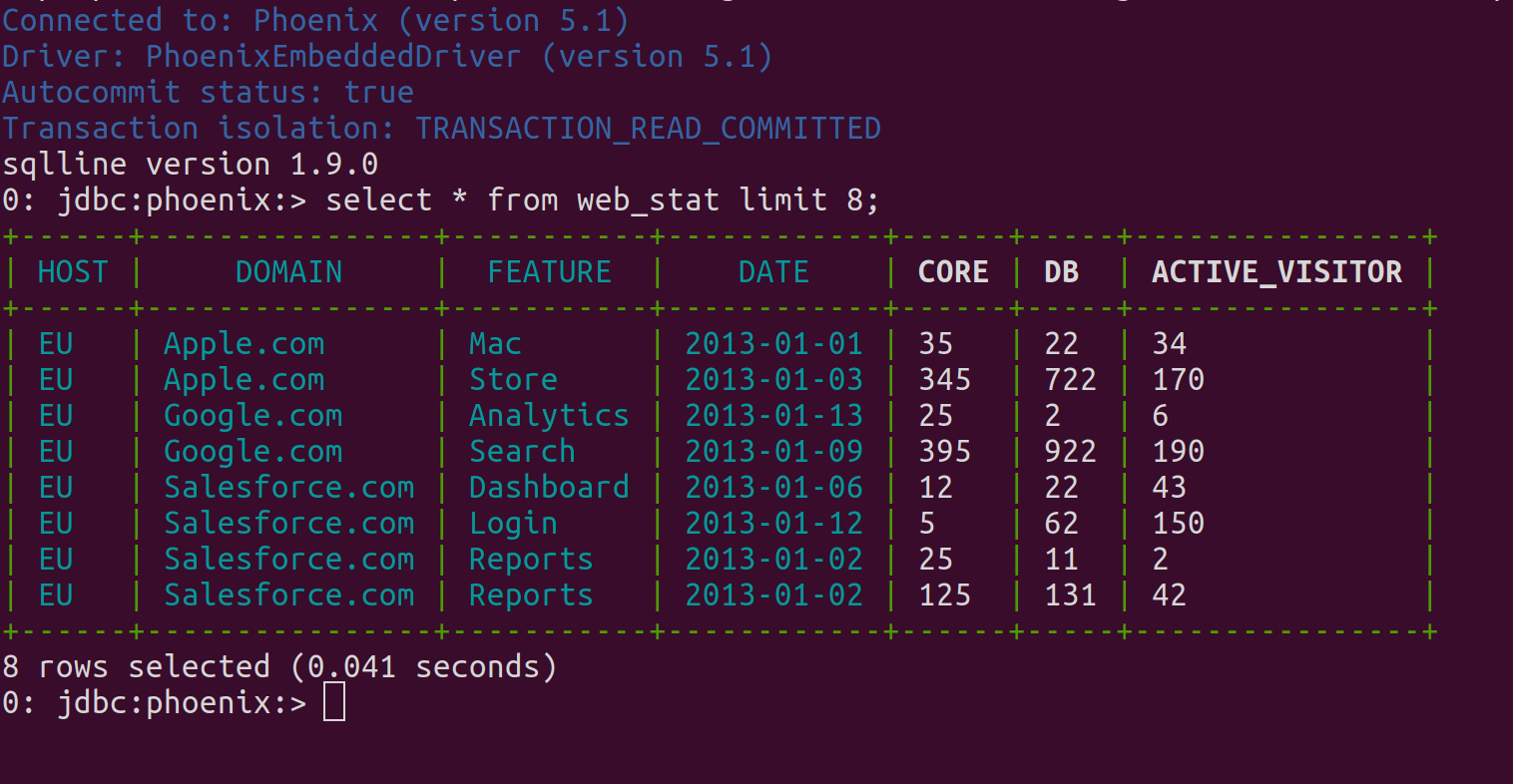
The Phoenix table WEB_STAT is created as an HBase table, and can be viewed normally from within the HBase UI:
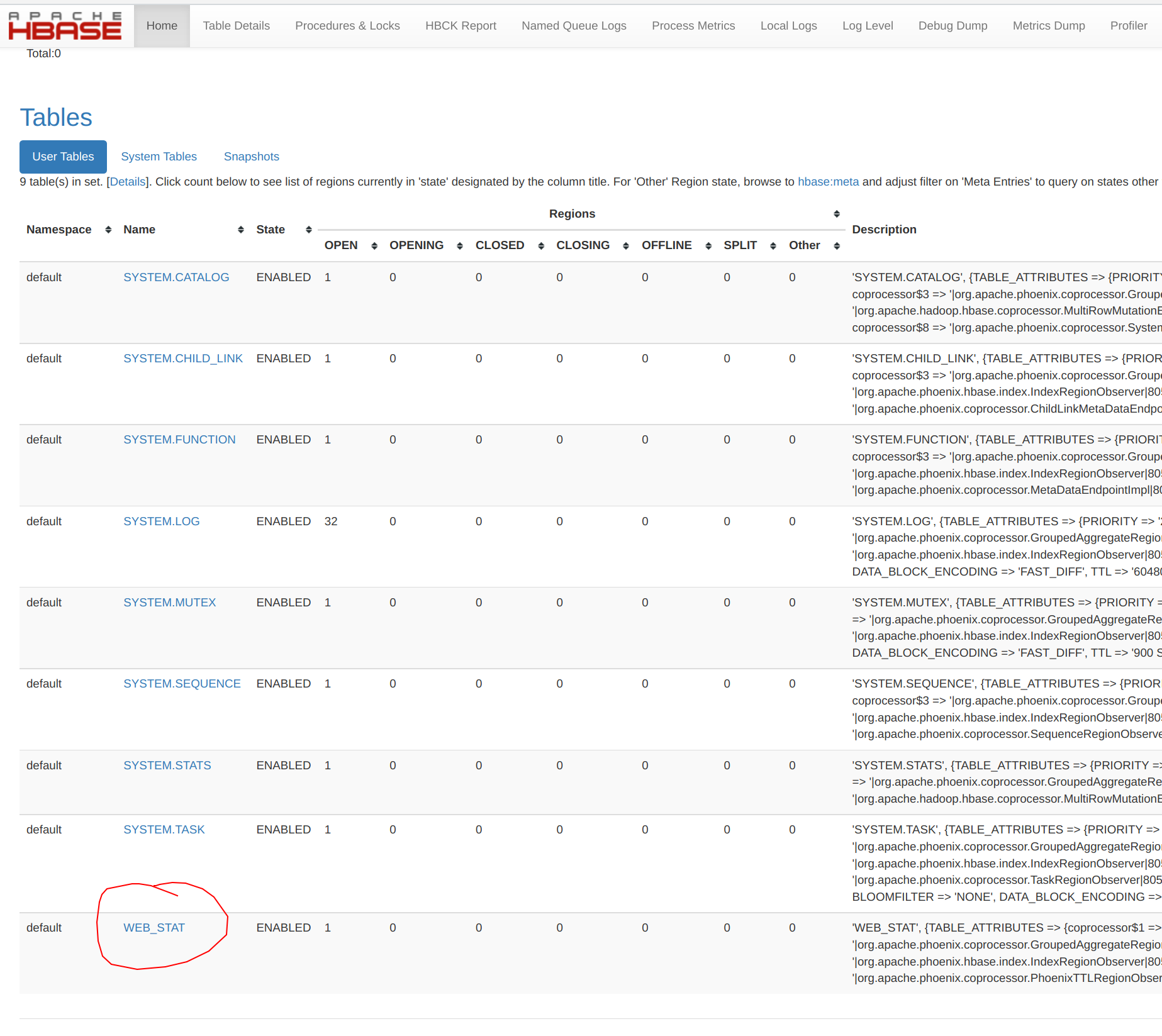
The SYSTEM* tables are those required by Phoenix and are created the first time that Phoenix is invoked.
Both psql.py and sqlline.py generate a java command that calls classes from the Phoenix client library .jar. The Zookeeper quorum does not need to be supplied as part of the URL used by the JDBC connection string, as long as the environment variable HBASE_CONF_DIR is set and supplied as an element for the -cp classpath search: the cluster information is then extracted from $HBASE_CONF_DIR/hbase-site.xml.
|