Usage
Database for the Superset metadata
The metadata of Superset (slices, connections, tables, dashboards, …) is stored in an SQL database.
For testing purposes, you can spin up a PostgreSQL database with the following command:
helm repo add bitnami https://charts.bitnami.com/bitnami
helm install superset bitnami/postgresql \
--set auth.username=superset \
--set auth.password=superset \
--set auth.database=supersetSecret with Superset credentials
A secret with the necessary credentials must be created, this entails database connection credentials as well as an admin account for Superset itself:
apiVersion: v1
kind: Secret
metadata:
name: simple-superset-credentials
type: Opaque
stringData:
adminUser.username: admin
adminUser.firstname: Superset
adminUser.lastname: Admin
adminUser.email: admin@superset.com
adminUser.password: admin
connections.secretKey: thisISaSECRET_1234
connections.sqlalchemyDatabaseUri: postgresql://superset:superset@superset-postgresql.default.svc.cluster.local/supersetThe connections.secretKey will be used for securely signing the session cookies and can be used
for any other security related needs by extensions. It should be a long random string of bytes.
connections.sqlalchemyDatabaseUri must contain the connection string to the SQL database storing
the Superset metadata.
The adminUser fields are used to create an admin user.
Please note that the admin user will be disabled if you use a non-default authentication mechanism like LDAP.
Creation of a Superset node
A Superset node must be created as a custom resource:
apiVersion: superset.stackable.tech/v1alpha1
kind: SupersetCluster
metadata:
name: superset
spec:
version: 1.5.1-stackable0.1.0
statsdExporterVersion: v0.22.4
credentialsSecret: simple-superset-credentials
loadExamplesOnInit: true
nodes:
roleGroups:
default:
config:
rowLimit: 10000metadata.name contains the name of the Superset cluster.
The label of the Docker image provided by Stackable must be set in spec.version.
Please note that the version you need to specify is not only the version of Apache Superset which you want to roll out, but has to be amended with a Stackable version as shown. This Stackable version is the version of the underlying container image which is used to execute the processes. For a list of available versions please check our image registry. It should generally be safe to simply use the latest image version that is available.
spec.statsdExporterVersion must contain the tag of a statsd-exporter Docker image in the Stackable repository.
The previously created secret must be referenced in spec.credentialsSecret.
The spec.loadExamplesOnInit key is optional and defaults to false, it can be set to true to load example data into Superset when the database is initialized.
The rowLimit configuration option defines the row limit when requesting chart data.
Initialization of the Superset database
The first time the cluster is created, the operator creates a SupersetDB resource with the same name as the cluster. It ensures that the database is initialized (schema created, admin user created).
A Kubernetes job is created which starts a pod to initialize the database. This can take a while.
Using Superset
When the Superset node is created and the database is initialized, Superset can be opened in the browser.
The Superset port which defaults to 8088 can be forwarded to the local host:
kubectl port-forward service/simple-superset-external 8088Then it can be opened in the browser with http://localhost:8088.
Enter the admin credentials from the Kubernetes secret:
If the examples were loaded then some dashboards are already available:
Authentication
Every user has to authenticate themselves before using Superset. There are multiple options to set up the authentication of users.
LDAP
Superset supports authentication of users against an LDAP server.
Have a look at the LDAP example and the general Stackable Authentication documentation on how to set it up.
In general, it requires you to specify a AuthenticationClass which is used to authenticate the users. In this example we assign all the users the Admin role once they log into Superset.
apiVersion: superset.stackable.tech/v1alpha1
kind: SupersetCluster
metadata:
name: superset-with-ldap-server-veri-tls
spec:
version: 1.5.1-stackable0.1.0
[...]
authenticationConfig:
authenticationClass: superset-with-ldap-server-veri-tls-ldap
userRegistrationRole: AdminAuthorization
Superset has a concept called Roles which allows you to grant user permissions based on roles.
Have a look at the Superset documentation on Security.
Connecting Apache Druid Clusters
The operator can automatically connect Superset to Apache Druid clusters managed by the Stackable Druid Cluster.
To do so, create a DruidConnection resource:
apiVersion: superset.stackable.tech/v1alpha1
kind: DruidConnection
metadata:
name: superset-druid-connection
spec:
superset:
name: superset
namespace: default
druid:
name: my-druid-cluster
namespace: defaultThe name and namespace in spec.superset refer to the Superset cluster that you want to connect. Following our example above, the name is superset.
In spec.druid you specify the name and namespace of your Druid cluster.
The namespace part is optional; if it is omitted it will default to the namespace of the DruidConnection.
The namespace for the Superset and Druid cluster can be omitted, in that case the Operator will assume that they are in the same namespace as the DruidConnection.
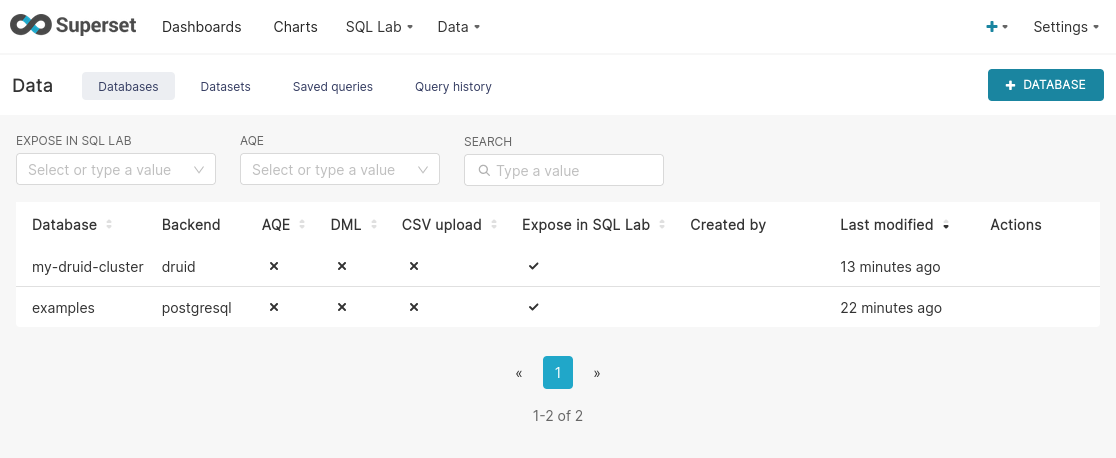
Once the database is initialized, the connection will be added to the cluster by the operator. You can see it in the user interface under Data > Databases:
Monitoring
The managed Superset instances are automatically configured to export Prometheus metrics. See Monitoring for more details.
Configuration & Environment Overrides
The cluster definition also supports overriding configuration properties and environment variables, either per role or per role group, where the more specific override (role group) has precedence over the less specific one (role).
Overriding certain properties which are set by the operator (such as the STATS_LOGGER)
can interfere with the operator and can lead to problems.
|
Configuration Properties
For a role or role group, at the same level of config, you can specify configOverrides for the
superset_config.py. For example, if you want to set the CSV export encoding and the preferred
databases adapt the nodes section of the cluster resource like so:
nodes:
roleGroups:
default:
config: {}
configOverrides:
superset_config.py:
CSV_EXPORT: "{'encoding': 'utf-8'}"
PREFERRED_DATABASES: |-
[
'PostgreSQL',
'Presto',
'MySQL',
'SQLite',
# etc.
]Just as for the config, it is possible to specify this at the role level as well:
nodes:
configOverrides:
superset_config.py:
CSV_EXPORT: "{'encoding': 'utf-8'}"
PREFERRED_DATABASES: |-
[
'PostgreSQL',
'Presto',
'MySQL',
'SQLite',
# etc.
]
roleGroups:
default:
config: {}All override property values must be strings. They are treated as Python expressions. So care must be taken to not produce an invalid configuration.
For a full list of configuration options we refer to the main config file for Superset.