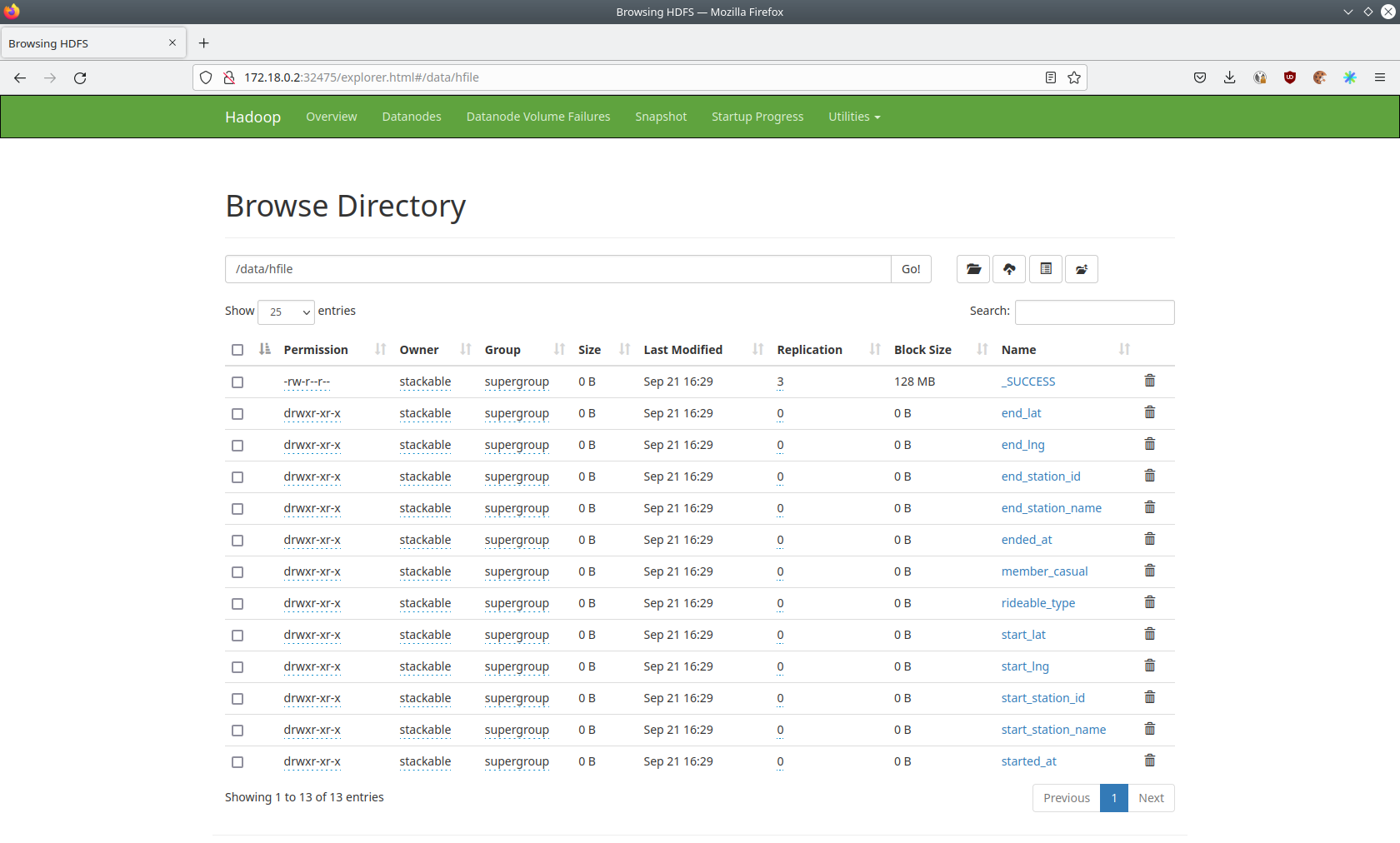
hbase-hdfs-cycling-data
|
This guide assumes that you already have the demo |
This demo will
-
Install the required Stackable operators
-
Spin up the follow data products
-
Hbase: A open source distributed scalable, big data store. This demos uses it to store the cyclistic dataset and enable access to it
-
HDFS: A distributed file system used to intermediately store the dataset before importing it into Hbase
-
-
Use distcp to copy a cyclistic dataset from an S3 bucket into HDFS
-
Create HFiles, which is a File format for hbase consisting of sorted key/value pairs. Both keys and values are byte arrays
-
Load Hfiles into an existing table via the
Importtsvutility, which will load data inTSVorCSVformat into HBase -
Query data via hbase shell, which is an interactive shell to execute commands on the created table
You can see the deployed products as well as their relationship in the following diagram:
List deployed Stackable services
To list the installed Stackable services run the following command:
stackablectl services list --all-namespaces
PRODUCT NAME NAMESPACE ENDPOINTS EXTRA INFOS
hbase hbase default regionserver 172.18.0.5:32282
ui http://172.18.0.5:31527
metrics 172.18.0.5:31081
hdfs hdfs default datanode-default-0-metrics 172.18.0.2:31441
datanode-default-0-data 172.18.0.2:32432
datanode-default-0-http http://172.18.0.2:30758
datanode-default-0-ipc 172.18.0.2:32323
journalnode-default-0-metrics 172.18.0.5:31123
journalnode-default-0-http http://172.18.0.5:30038
journalnode-default-0-https https://172.18.0.5:31996
journalnode-default-0-rpc 172.18.0.5:30080
namenode-default-0-metrics 172.18.0.2:32753
namenode-default-0-http http://172.18.0.2:32475
namenode-default-0-rpc 172.18.0.2:31639
namenode-default-1-metrics 172.18.0.4:32202
namenode-default-1-http http://172.18.0.4:31486
namenode-default-1-rpc 172.18.0.4:31874
zookeeper zookeeper default zk 172.18.0.4:32469|
When a product instance has not finished starting yet, the service will have no endpoint. Starting all the product instances might take a considerable amount of time depending on your internet connectivity. In case the product is not ready yet a warning might be shown. |
The first Job
DistCp (distributed copy) is a tool used for large inter/intra-cluster copying. It uses MapReduce to effect its distribution, error handling, recovery, and reporting. It expands a list of files and directories into input to map tasks, each of which will copy a partition of the files specified in the source list. Therefore, the first Job uses DistCp to copy data from a S3 bucket into HDFS. Below you’ll see parts from the logs.
Copying s3a://public-backup-nyc-tlc/cycling-tripdata/demo-cycling-tripdata.csv.gz to hdfs://hdfs/data/raw/demo-cycling-tripdata.csv.gz
[LocalJobRunner Map Task Executor #0] mapred.RetriableFileCopyCommand (RetriableFileCopyCommand.java:getTempFile(235)) - Creating temp file: hdfs://hdfs/data/raw/.distcp.tmp.attempt_local60745921_0001_m_000000_0.1663687068145
[LocalJobRunner Map Task Executor #0] mapred.RetriableFileCopyCommand (RetriableFileCopyCommand.java:doCopy(127)) - Writing to temporary target file path hdfs://hdfs/data/raw/.distcp.tmp.attempt_local60745921_0001_m_000000_0.1663687068145
[LocalJobRunner Map Task Executor #0] mapred.RetriableFileCopyCommand (RetriableFileCopyCommand.java:doCopy(153)) - Renaming temporary target file path hdfs://hdfs/data/raw/.distcp.tmp.attempt_local60745921_0001_m_000000_0.1663687068145 to hdfs://hdfs/data/raw/demo-cycling-tripdata.csv.gz
[LocalJobRunner Map Task Executor #0] mapred.RetriableFileCopyCommand (RetriableFileCopyCommand.java:doCopy(157)) - Completed writing hdfs://hdfs/data/raw/demo-cycling-tripdata.csv.gz (3342891 bytes)
[LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(634)) -
[LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:done(1244)) - Task:attempt_local60745921_0001_m_000000_0 is done. And is in the process of committing
[LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(634)) -
[LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:commit(1421)) - Task attempt_local60745921_0001_m_000000_0 is allowed to commit now
[LocalJobRunner Map Task Executor #0] output.FileOutputCommitter (FileOutputCommitter.java:commitTask(609)) - Saved output of task 'attempt_local60745921_0001_m_000000_0' to file:/tmp/hadoop/mapred/staging/stackable339030898/.staging/_distcp-1760904616/_logs
[LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(634)) - 100.0% Copying s3a://public-backup-nyc-tlc/cycling-tripdata/demo-cycling-tripdata.csv.gz to hdfs://hdfs/data/raw/demo-cycling-tripdata.csv.gzThe second Job
The second Job consists of 2 steps.
First, we use org.apache.hadoop.hbase.mapreduce.ImportTsv (see ImportTsv Docs) to create a table and Hfiles.
Hfile is an Hbase dedicated file format which is performance optimized for hbase. It stores meta information about the data and thus increases the performance of hbase
When connecting to the hbase master and opening a bin/hbase shell and executing list, you will see the created table. However, it’ll contain 0 rows at this point.
You can connect to the shell via
kubectl exec -it hbase-master-default-0 -- bin/hbase shellIf you use k9s you can go into the hbase-master-default-0 and execute bin/hbase shell list.
TABLE
cycling-tripdataSecondly, we’ll use org.apache.hadoop.hbase.tool.LoadIncrementalHFiles (see see bulk load docs) to import the Hfiles into the table and ingest rows.
You can now use the bin/hbase shell again and execute count 'cycling-tripdata' and see below for a partial result.
Current count: 1000, row: 02FD41C2518CCF81
Current count: 2000, row: 06022E151BC79CE0
Current count: 3000, row: 090E4E73A888604A
...
Current count: 82000, row: F7A8C86949FD9B1B
Current count: 83000, row: FA9AA8F17E766FD5
Current count: 84000, row: FDBD9EC46964C103
84777 row(s)
Took 13.4666 seconds
=> 84777The table
You can now use the table and the data. You are able to use all available hbase shell commands. Below, you’ll see the table description.
describe 'cycling-tripdata'
Table cycling-tripdata is ENABLED
cycling-tripdata
COLUMN FAMILIES DESCRIPTION
{NAME => 'end_lat', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'end_lng', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'end_station_id', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'end_station_name', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'ended_at', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'member_casual', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'rideable_type', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'start_lat', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'start_lng', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'start_station_id', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'start_station_name', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}
{NAME => 'started_at', BLOOMFILTER => 'ROW', IN_MEMORY => 'false', VERSIONS => '1', KEEP_DELETED_CELLS => 'FALSE', DATA_BLOCK_ENCODING => 'NONE', COMPRESSION => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', BLOCKCACHE => 'true', BLOCKSIZE => '65536', REPLICATION_SCOPE => '0'}The Hbase UI
The Hbase web UI will give you information on status and metrics of your Hbase cluster.
If the UI is not available please do a port-forward kubectl port-forward hbase-master-default-0 16010
See below for the startpage.
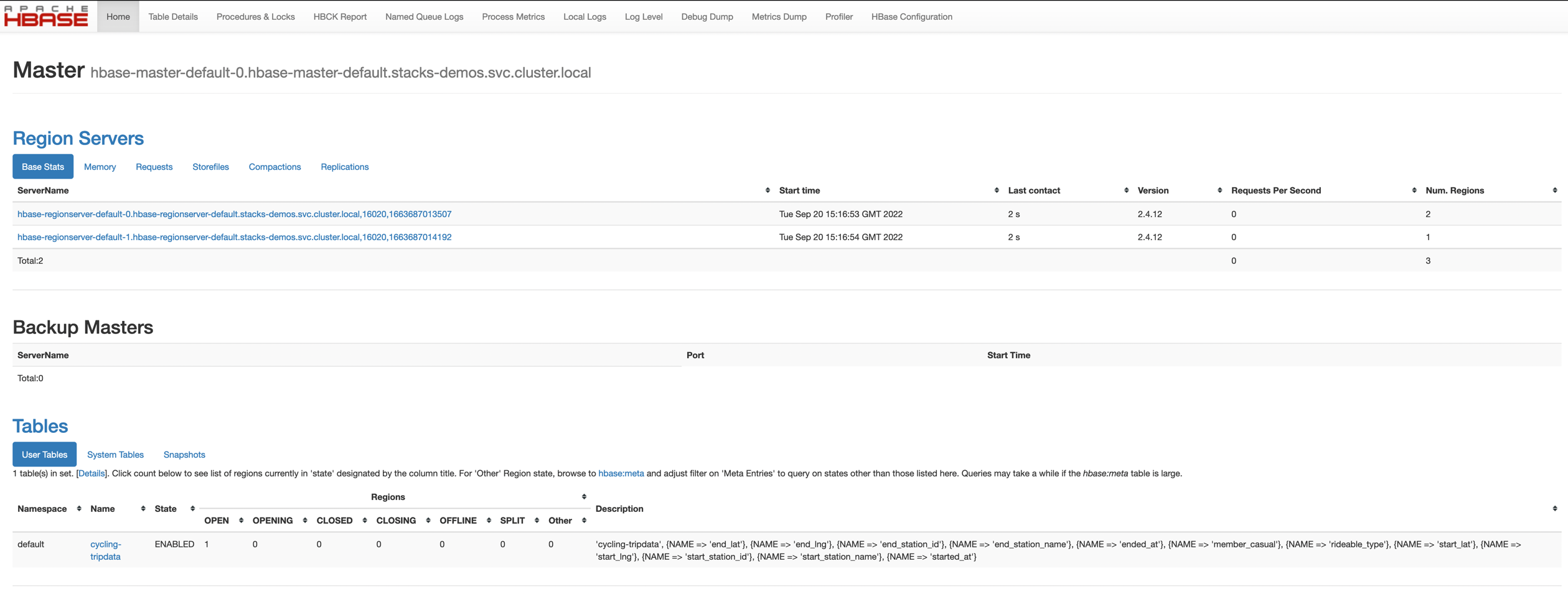
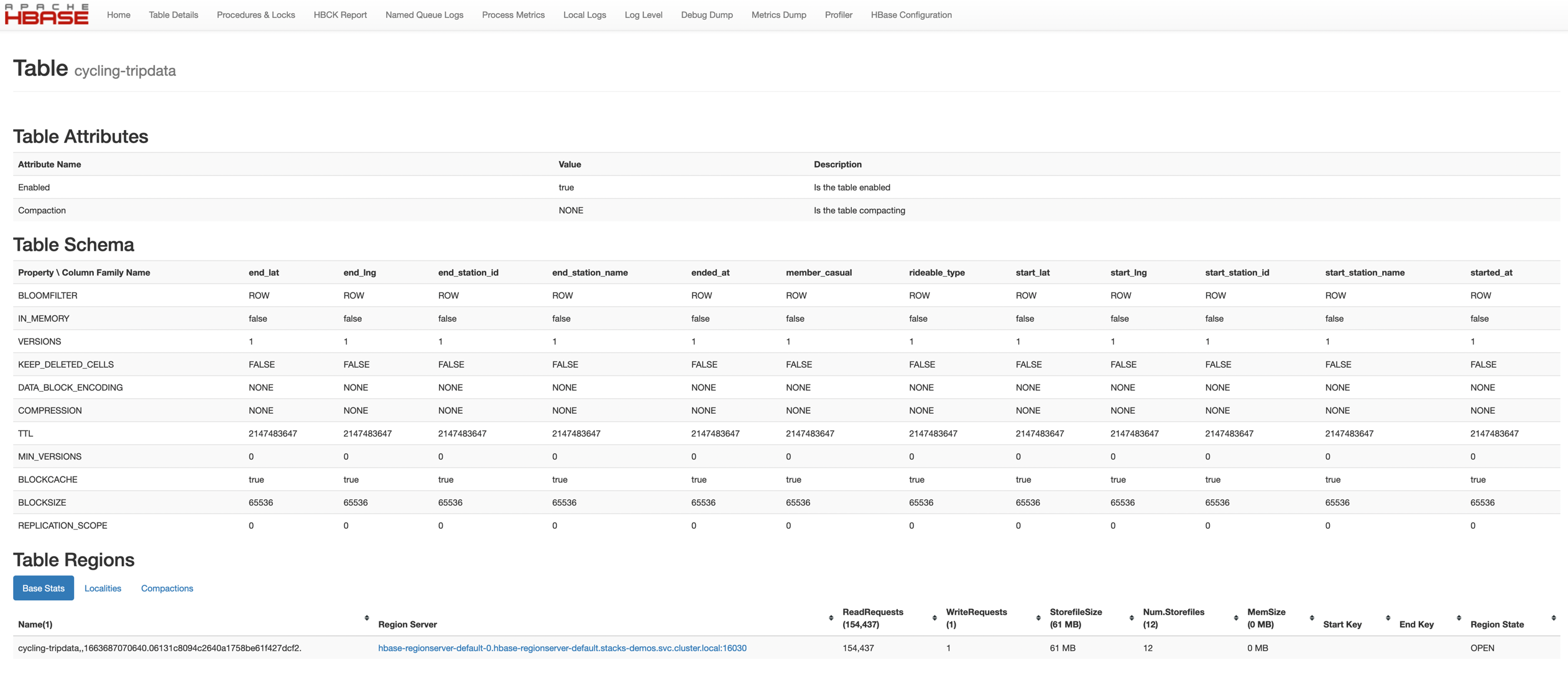
From the startpage you can check more details. For example details on the created table.
The HDFS UI
|
The hdfs services will be available with the next release 22-11 via |
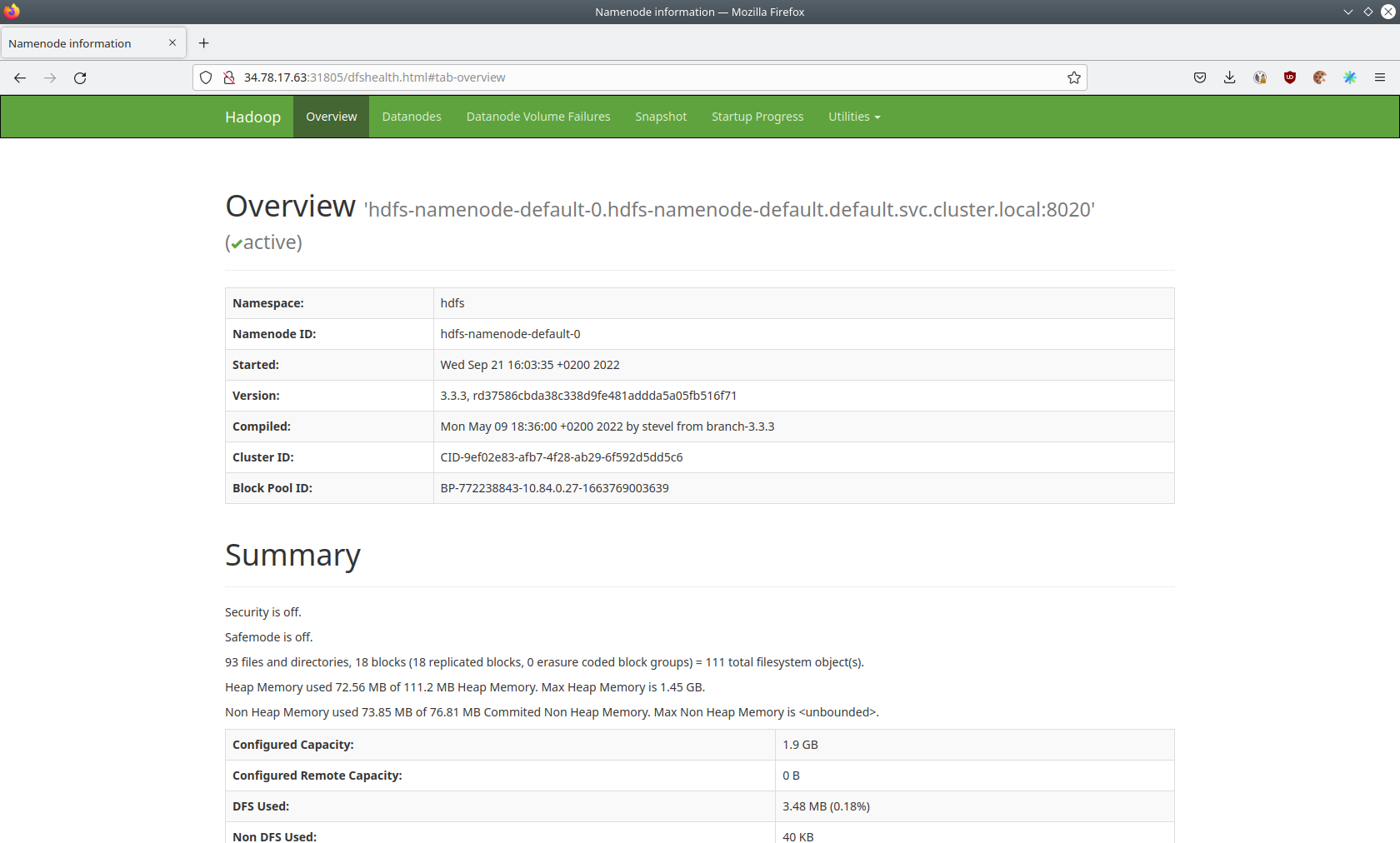
You can also see HDFS details via a UI. Below you will see the overview of your HDFS cluster
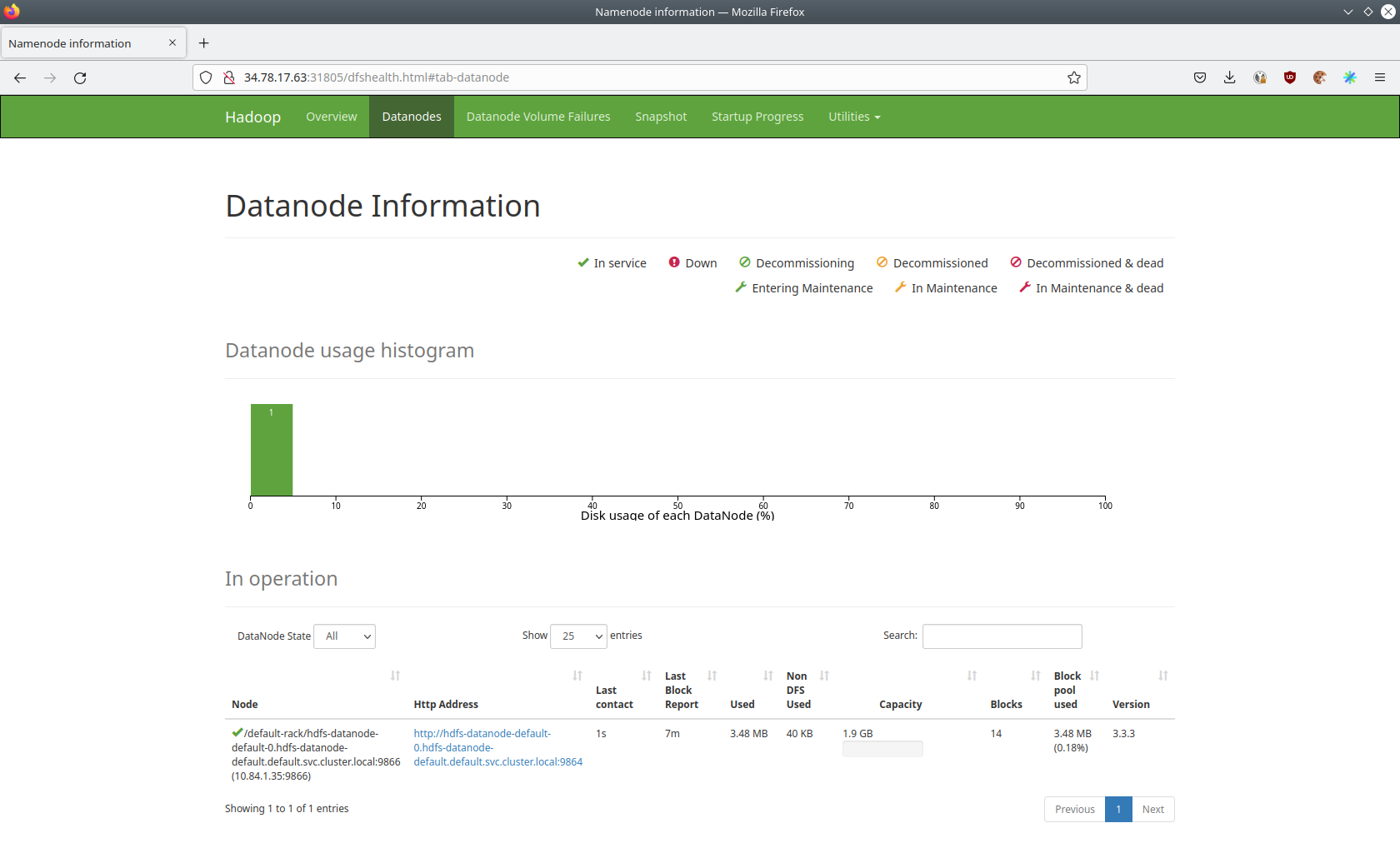
The UI will give you information on the datanodes via the datanodes tab.
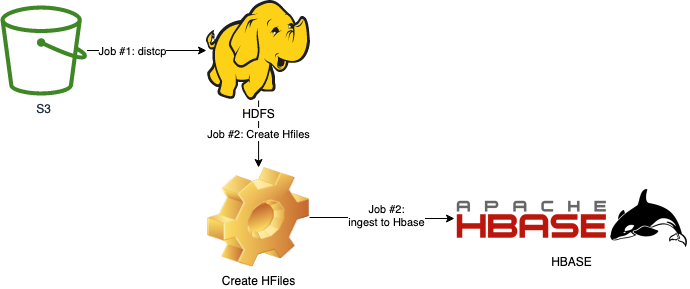
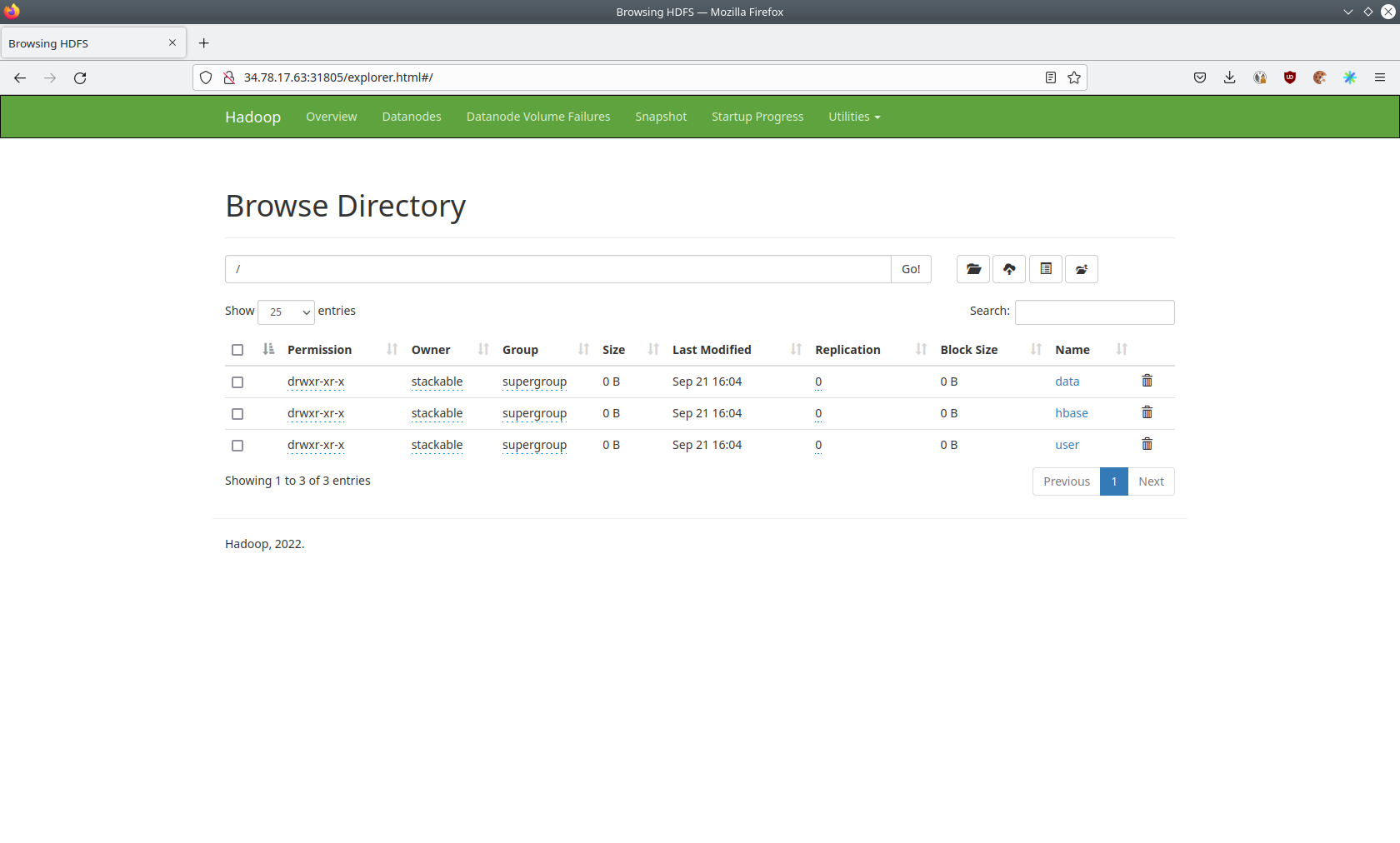
You can also browse the directory with the UI.
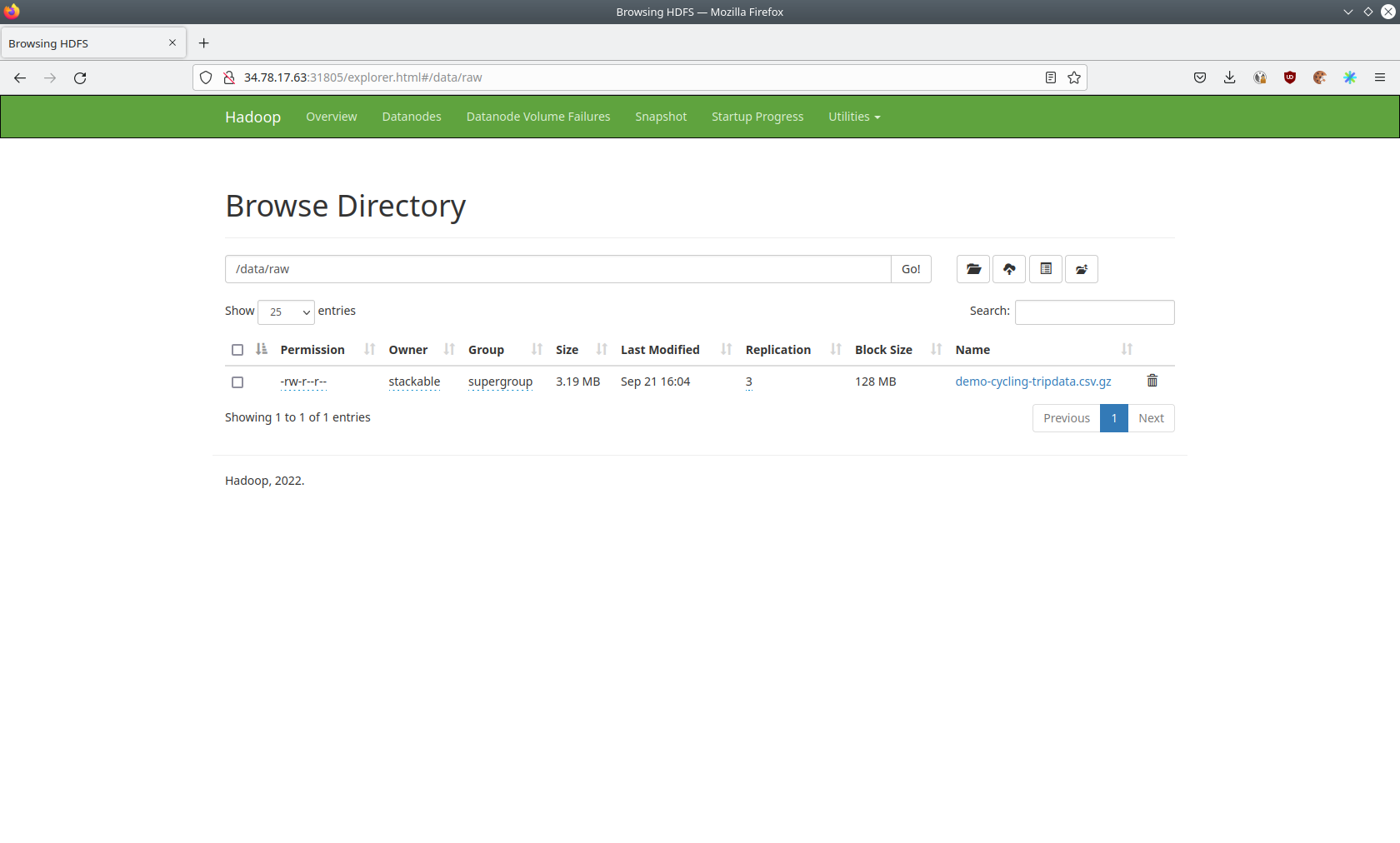
The raw data from the distcp job can be found here.
The structure of the Hilfes can be seen here.